Data standards
We have a tool suite that is designed to work with data from any hub.
Model Tasks Schema Target Data Formats Model Output Formats
The core of the hubverse are the robust and flexible data standards that allow administrators to write structured guidelines for tabular model output submissions that can be easily validated, ensembled, and visualized.
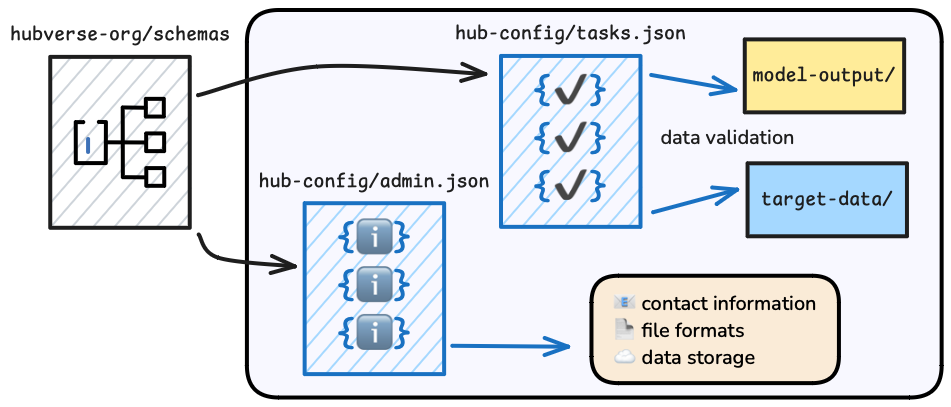
Understanding Model Tasks
Each hub starts with a file called hub-config/tasks.json that defines model tasks and frequency of submission. The structure of this file is defined by the hubverse model tasks schema.
The tasks.json file is responsible for validation of all model submissions and ensures that data are inter-operable.
A model task defines the expected content of a tabular model submission against one or more modeling targets. It includes three properties:
- Task ID variables: a collection of variables and their expected values used for modeling efforts (for example:
target(incident hospitalizations),location(Massachusettes),reference_date(2025-04-16), andhorizon(-1)) - Output types: The method modelers should use to summarize the results of their modeling efforts (for example: the
quantileprobabilities 0.01, 0.025, 0.5, 0.975, 0.99) - Target metadata: The caracteristics of the value modelers are trying to predict (for example, incident hospitalizations represent weekly step-ahead continuous count data)
Model Output
Model outputs are provided by modeling teams. The hubverse does not limit how models are constructed or what software they are run in. The only requirement is that the model output must be in a tabular format (specified in the hub’s admin.json file).
The model output format is a tabluar representation of model output defined by the Model Tasks for a given hub. You can find examples of model output and more in the model output formats page of the official documentation.
Target Data
The target data are represented in two files: time-series and oracle-outputs1. Each data format is useful for different purposes (see table below). Modelers will most often estimate model parameters by fitting to the raw data in time series format.
| Data Format | Model Estimation | Plotting | Evaluation |
|---|---|---|---|
| Time series | ✅ | ✅ | |
| Oracle output | ✅ | ✅ |
You can read more in the target data page of the official documentation.
Data Storage (GitHub, AWS)
All hub data are stored within the hub itself and submissions are commonly managed through GitHub.
The hubverse team currently provides cloud hosting for hubs. A “cloud-enabled” hub is one that mirrors its data and configuration to an Amazon Web Services (AWS) S3 bucket. By default, the current hub directories are synced in near-real-time to AWS:
- auxiliary-data
- hub-config
- model-abstracts
- model-metadata
- model-output
- target-data
If you are interested in storing your data on AWS S3, please consult the AWS onboarding guide
Footnotes
oracle outputs are generated from time series↩︎